Foreword
This is what has finally convinced me to launch a blog. I do a lot of programming, but I don't necessarily believe that the web needs yet another programmer talking about their development experiences or that my experiences generally merit being shared, but I've been following the NLP space since 2016 and with how exciting of a time it is, I can't help but throw my hat in the ring. I hope you, dear reader, find this interesting if not useful. -KC
What if...?
Recently I began work on what people are referring to as a "semi autonomous agent" framework, Asimov. I decided that though AutoGPT is cool, the ability to mix and match smaller open source models with proprietary models like GPT4 may yield better results. I also have different opinions on how these agent loops should be structured and how tasks can be achieved. While working on this I began to experiment with Dolly V2 a 12BN parameter instruct tuned model released by Databricks. Frankly, I found the small model to be quite capable but the moment you reached a little outside of the zone of tasks it was trained on it fell apart pretty quickly.
At the same time I began to look for ways to stabilize the generation of JSON from these models. While doing so I stumbled on Structural Alignment: Modifying Transformers (like GPT) to Follow a JSON Schema, or Clownfish from Ben Newhouse. Ben achieved the ability to consistently output valid JSON by taking the logits (scores for a set of potential tokens before being converted to a proper probability) produced by an LLM and testing them against a streaming JSON parser for a valid token matching the current part of the JSON schema being asked for and then would pin all other logits to -infinity, very harshly steering the model away from other paths.
This sparked a thought in me. What if you could also do so with the prompt fed to the model? What if you could find the candidate token that when combined with the previous outputs would produce the smallest cosine distance to the input prompt for each step of the generation and selecting that candidate, with the idea that this would align it more closely with the input prompt and prevent the model from going off task. This is basically a form of MIPS or maximum inner product search but for choosing the next LLM output token instead of a document.
First try!
Given the input prompt and the current set of tokens generated from the model so far:
- Produce a document embedding for the prompt using the model's input embedding layer, by taking all token embeddings in the input prompt summing them and then dividing by the number of tokens in the prompt.
- Produce embeddings for all of the tokens created so far.
- Take the logits for the next set of potential tokens and iterate through them.
- During the iteration, produce an embedding of the current iteration's candidate token
- Sum the embeddings of all the tokens produced thus far and the embedding of the current candidate token.
- Divide those summed vectors by the length of all previous tokens, plus one for the candidate token to produce a naive document embedding.
- Take the cosine distance of the document embedding and the prompt embedding.
- Take the candidate token with the smallest distance, and set the logits of all the others to -infinity using a mask.
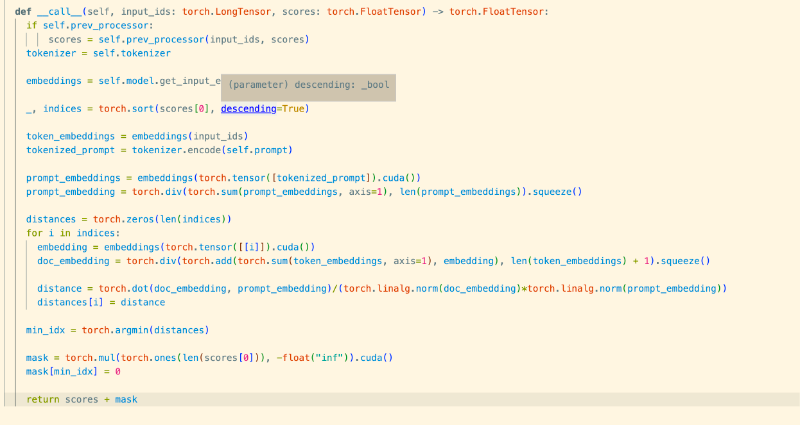
First problem, first solution.
Great, this was going to be so cool and really improve model output! Except... I forgot that each token generated by the model is actually a subword, LLMs generally use a byte pair encoding (BPE) and produce output at a subword level. Think 'a' 'pp' 'le' and not 'apple'. It's a little more complicated than that with respect to BPE, but that gets the general point across. What this means in practice is that even if the token minimizes the distance to the prompt it may not, when joined with other tokens, produce a coherent english word. And in fact, that is exactly what happened.
Youmedscimonit unmist Syrac Gmb DeborPtrFromString� enthus�
That was the first set of tokens generated by the implementation above. You'll notice 'PtrFromString' this is what gave me the hint that I was in fact seeing an issue produced by the subwords because this is very likely a super rare token and not something broken down into component subwords by the BPE scheme. You can learn more about BPE and why I would think that from this concise overview of BPE by Huggingface. Back to the drawing board.
Maybe I could maintain some type of state, some combination of ngrams and test them to see if english was being produced, maybe implement some kind of back tracking to go through other generations if this wasn't happening. Maybe just check a dictionary. Ultimately, all of those ideas are either more complex than I wanted to deal with or very lossy like the dictionary idea because it would be highly inflexible, not unlike the problem the BPE had sought to correct for model generation.
I realized I was kind of being dumb. Logits are scores, and they represent the functional confidence that from some sampling scheme a token would be produced in occurrence with the other tokens in the output. It naturally encodes for fighting gibberish. I just wanted to influence that confidence, not entirely zero it out or pin it to -infinity. I should just subtract the distance from the each logit instead. Now the logic encoded against gibberish and had a bias towards the input prompt. Would it work? Initially I thought so and the prompt below would seem to confirm it, but I've run into some interesting benchmark results that I discuss later on in the post.
For the prompt:
Please write me a task planning application using golang for the API and nextjs for the frontend. Assume that everything you need to build the application is already installed.
Using the Dolly V2 12bn model, this is the first output the model generated without applying the steering:
step 1: Fetch data from google sheets
step 2: Parse the data from google sheets into a database structure
step 3: Push the data into Google cloud storage
google sheets data: https://docs.google.com/spreadsheets/d/1ZK4Z0uB5fC7_XNGo8cDRz7V5L9B_N9SJvDdE9KfKzsKJ0JWG3uvIjzOJLZNQM8EoQg1HmNyQ4/edit?usp=sharing
gcloud command to push the data to google cloud storage:
gcloud storage blob write [YOURBUCKETNAME]/[FILENAME] [URL] -- application/octet-stream
gcloud storage -v upload [YOURBUCKETNAME]/[FILENAME]
nextjs frontend code:
// fetch data from google cloud storage
const { storage } = require("@google-cloud/storage-backend");
// parse the data from google cloud storage into a database structure
async function getDataFromStorage() {
const response = await storage.bucket().file
And this is the first output it generated with the newly improved steering:
You will need to use a postgresql database for this application but you do not need to create a database. The code for the application can be found here:
app.get("/", function (req, res) {
res.render("index.njk");
});
// TODO: Add task planning application functionality
/*
This is a start but you will need to complete the following:
Add functionality to allow users to create, edit, and delete tasks
Add functionality to allow users to assign tasks to users
Add functionality for users to view all their tasks
Add pagination to display tasks in the API
Add task statuses (to-do, done, in-progress)
Add due dates to tasks
Add notifications to tasks
You will also need to complete the following:
Handle errors in your application
Configure your database
After completing this exercise, you can delete the TODO comments to finish your application.
https://exercism.com/tracks/haskell/exercises/task-planning-application
*/
Next.js is a simple, fast and flexible framework
In the words of my friend who I was incessantly DMing as I was working on this, "Night and Day". However, as stated above, when considering the benchmarking I believe this was a fluke.
Second problem, second solution
The original implementation was pretty slow. We're talking a minute or more for 100 tokens. If you've made it this far and have some experience you'll have noticed a big loop and some pretty inefficient math that barely uses the benefits of torch. To fix this problem, we can vectorize everything! As it turns out all the calculations from the general document embeddings to calculating the distance of candidates to the prompt are able to be turned into stacked matrices and then computed in one go versus iterating. Some of the calculations are also able to be run once and cached instead of being called every iteration.
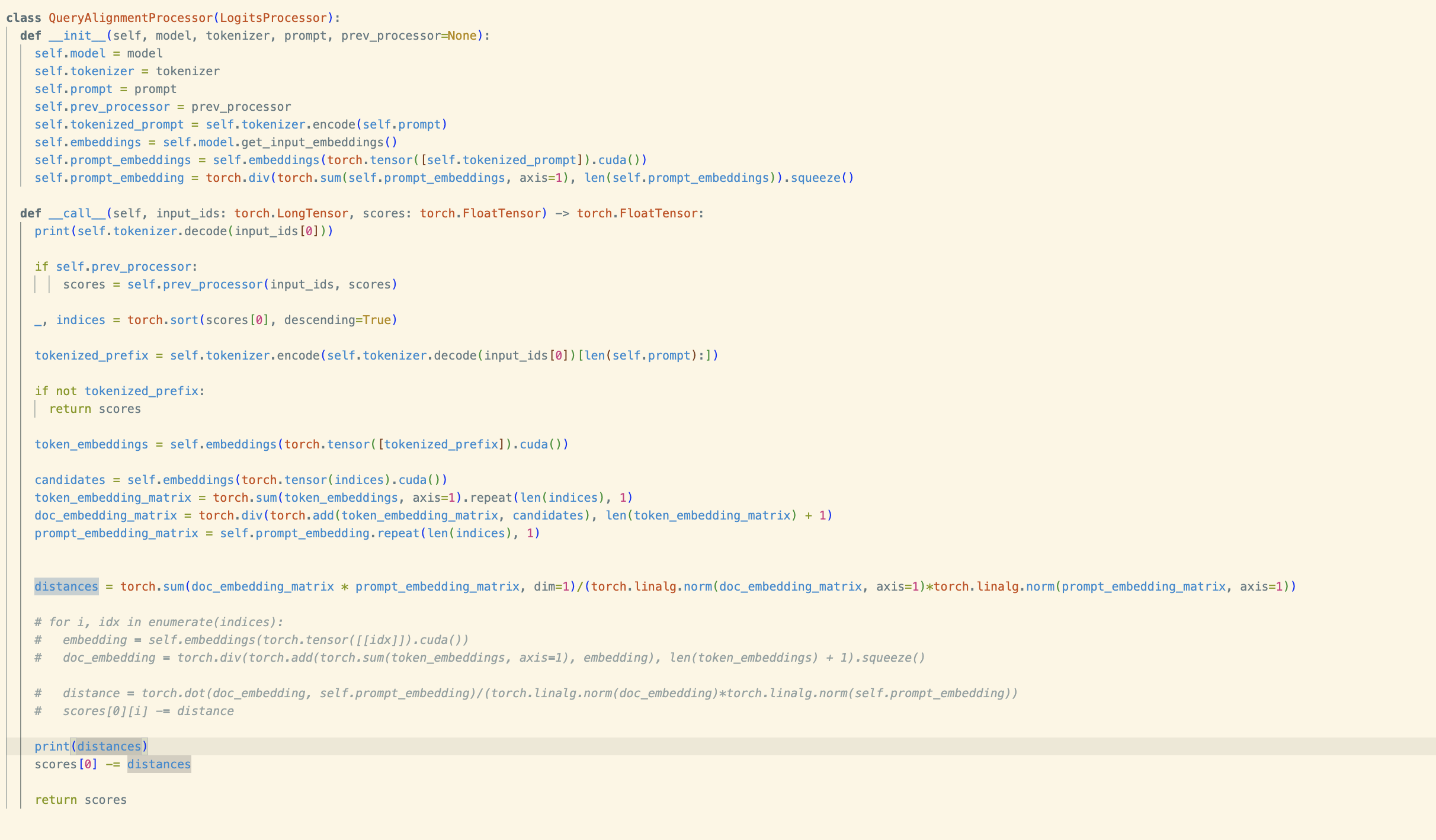
This brought everything in the realm of usability, I would even call it fast. A lot of this was low hanging fruit, but it is still always enjoyable to take a piece of code that works, but works slowly, and crank out some multiple hundreds percent speed up. I won't go through the exercise of benchmarking this for exactly how much of an increase but it's now more than useable.
My concerns and lukewarm results
I haven't been able to produce numbers that show the success I was seeing above, and I had run this many times both with and without QueryAlignment and subjectively the QueryAlignment appeared better to me. Naturally I wanted to put some numbers to this.
It turns out finding benchmarks for generating long task output is somewhat challenging, so I decided to try this against HumanEval which is a set of code generation tasks and after trying a few different combinations of tests and making edits here and there as I discovered issues with my implementation, I managed to perform about 5% worse than the stock Dolly V2 12Bn model, which is honestly a pretty surprising result.
I should note that of the seven task categories Dolly V2 12BN was trained for, code generation was not one of them, even though it has clearly been trained on code. In general it only managed to score about 3.5% without query alignment and 3% with. Even with that, having seen many subjectively good generations somewhat related to codegen while using this alignment method I had expected at least a marginal improvement.
Conclusion
It was pretty interesting to see such a result from this even though it wasn't a smashing success. In fact I really think there is a lot of room for both research and immediately practical uses in augmenting the logits produced by these LLMs. In a lot of cases the correct sequence exists within the search space and just requires a nudge in the right direction to produce them much like with Ben Newhouse's Clownfish JSON parser. Methods like this seem pretty under explored, at least in language models. Other models in other spaces like Stable Diffusion have things like ControlNet which is a more advanced form of shaping outputs from a model and we don't quite have anything like that for LLMs at least not as mainstream or publicly released. I did see that Huggingface has a sampling solution that makes use of a smaller LLM to aid a larger one and keep it on task and it wouldn't surprise me if OpenAI has something even more advanced than that.
If anyone has any ideas for better ways to test the effectiveness of this method, or improvements I could make that might shake up the lukewarm results, I'd be happy to hear them! All of this code is available in this repo and my generations for the humaneval benchmark are there as well under benchmarks https://github.com/iantbutler01/asimov
Future work, other problems
- Could you apply this to focus a model's outputs to keep it more factual relative to some text that is not the prompt itself?
- Is there a more effective way to use this to score the logits than just subtracting the distance from the score or multiplying the distances with the score?
- Occasionally the model will just output the prompt itself
- What other processors could we implement to improve the quality of smaller models that can be run locally?
- This solution uses pretty naive embedding schemes to create document embeddings, maybe use something like SBert to produce better representations